Patient data processed to provide a single instance of cleansed and normalised data.
The Voror team design, architect, develop, and support an open-source solution designed to aggregate patient data from multiple sources into a common ontology and model for driving better patient outcomes, research, and analytics in one package.
Common data model
We collect data, regardless of source, format or code system, to build a single picture for real-time direct care, population health, planning and research.
Advancing Healthcare Services
We provide data and information solutions that improve and support healthcare services. Using one of the world’s largest near real-time databases, those services help professionals to access population health and care data, across multiple health and care providers.
Secure normalised data
We aggregate coded patient data, in any format, map it to a single coding system/ontology, using the Information Model, and store it in a secure scalable database.
Information Model
Voror develop the open-source Health Information Model, in partnership with Endeavour Health Charitable
Trust. This combines a common ontology (mapping local and legacy codes), a
common logical data model, a collection of
code
sets, and a collection of queries.
This allows simpler analysis and extraction of the data, using only SNOMED codes and without
requiring any knowledge of the underlying
physical data model.
The information model contains over 11.4 million total concepts, increasing daily, comprising of:
- Ontological concepts (such as SNOMED, READ2, CTV3, ICD10, OPCS4, EMIS local, TPP Local, Cerner Millennium local)
- Data models (such as Clinical, Demographic, Provenance, Administration)
- Code sets (such as ClinRisk, QOF, SNOMED Foundation, Discovery project)
- Queries (such as Urgent Care decision support, QMUL CEG)
Normalisation of data
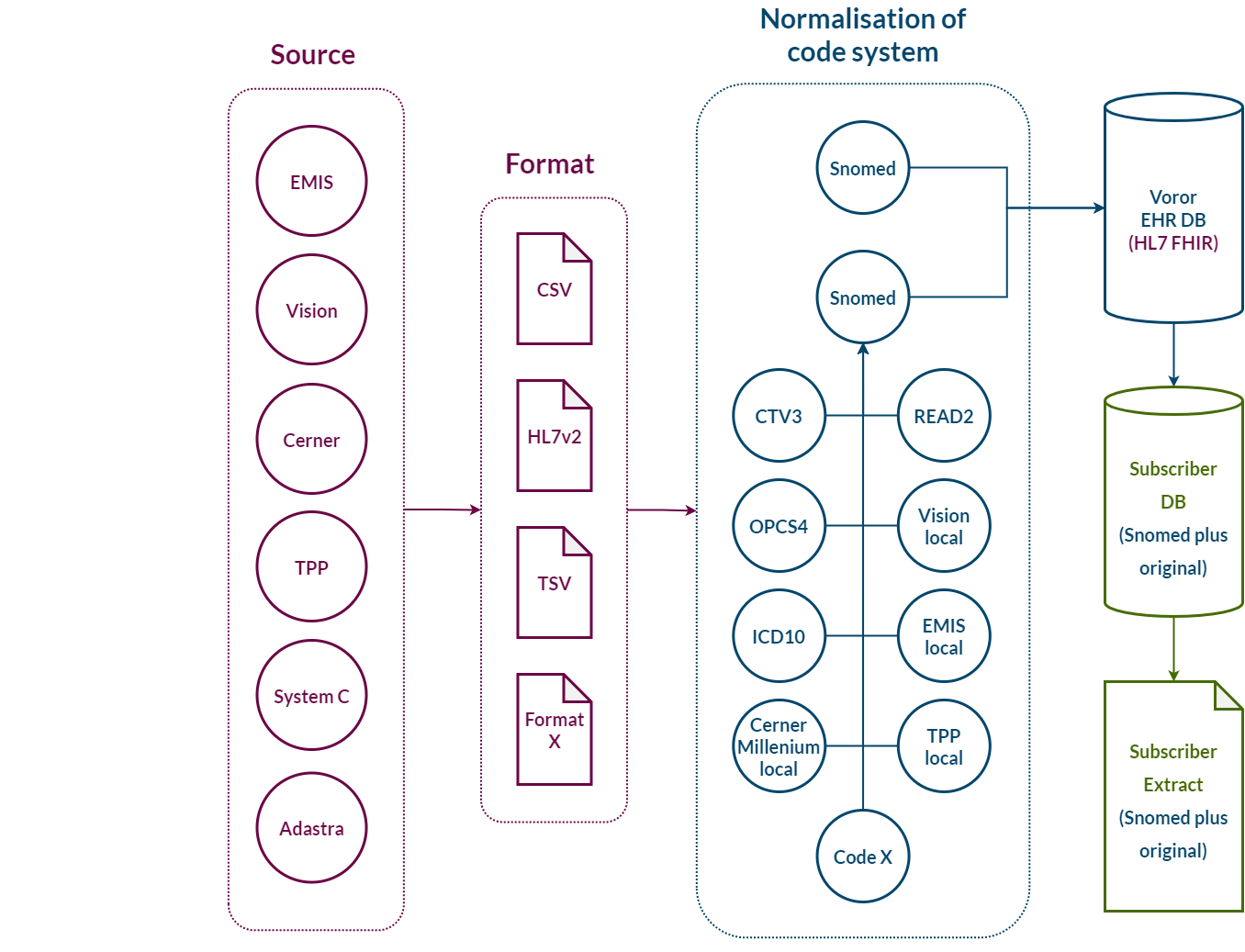
Any source, any format, any code system
Publisher to Subscriber data flow

Collect once - use many times
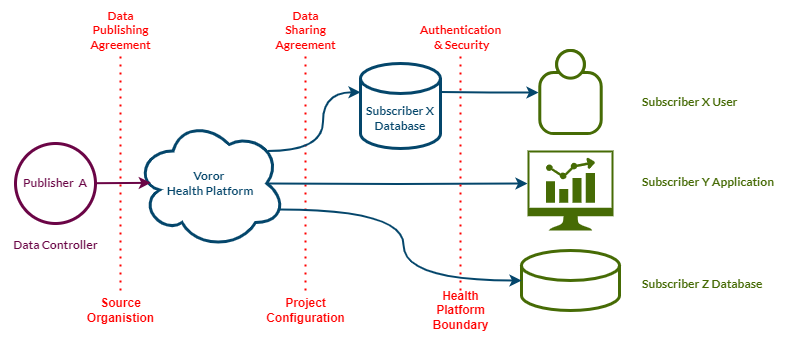
From a publisher's point of view